Stefan Haller
June 19, 2026
KI hat den Wiki-Markt erobert. Jede große Plattform bietet mittlerweile in irgendeiner Form KI-gestütztes Schreiben, semantische Suche oder dialogbasierten Wissensabruf an. Für Teams in nicht regulierten Umgebungen dreht sich die Entscheidung hauptsächlich um Funktionen und Preis. Für Organisationen, die in regulierten Branchen, in der öffentlichen Verwaltung oder an anderen Orten mit sensiblen Daten tätig sind, hat die Entscheidung jedoch weitreichendere Konsequenzen: Wer kontrolliert, was die KI mit Ihrem Wissen macht, und nach welchen Gesetzen?
Die heute verfügbaren Wiki-Plattformen verfolgen nicht alle denselben Ansatz in Bezug auf KI. Das Verständnis der Architekturmodelle – und was jedes einzelne für die Datenverwaltung bedeutet – ist hilfreicher als der Vergleich von Funktionslisten, die sich häufig ändern. Die Architektur ändert sich hingegen selten.
Wenn eine Wiki-Plattform KI-Funktionen hinzufügt, ergeben sich sofort mehrere Fragen:
Die Antworten hängen fast ausschließlich davon ab, welches der drei Architekturmodelle eine Plattform verwendet.
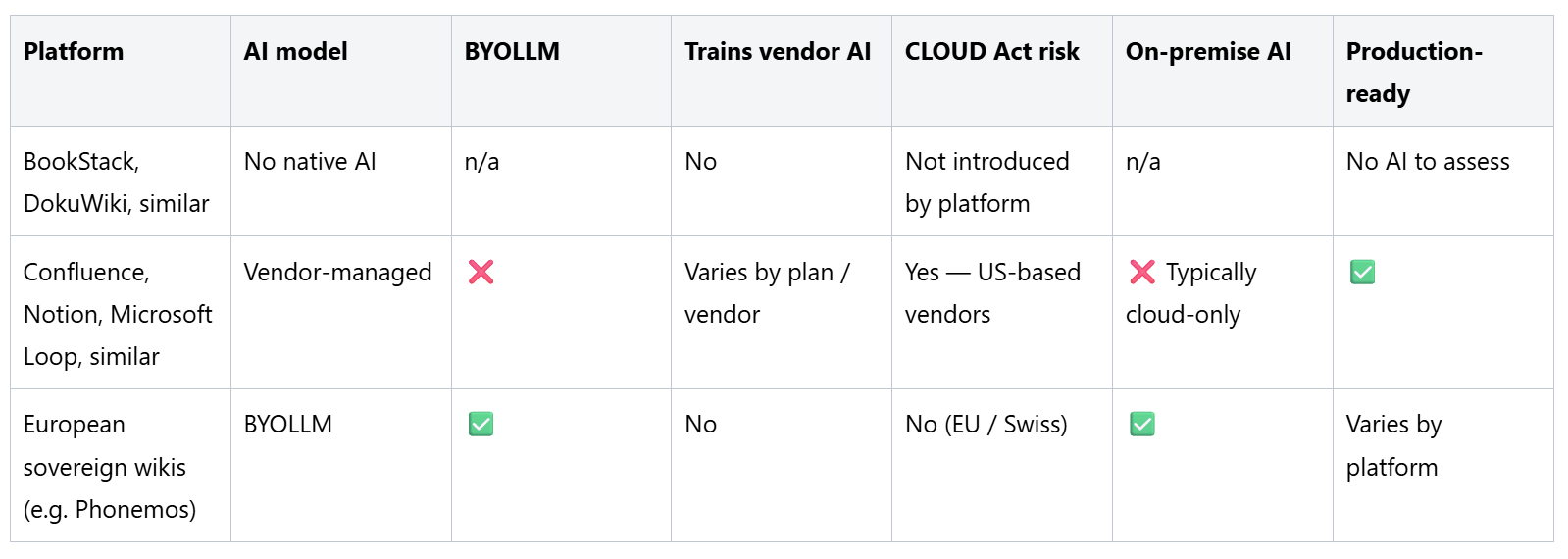
Einige Wiki-Plattformen bieten überhaupt keine KI-Funktionen. Die Suche erfolgt auf Basis von Schlüsselwörtern. Es gibt keine Inhaltsgenerierung, keinen semantischen Abruf und keinerlei LLM-Integration. KI-Funktionalität erfordert bei Bedarf eine individuelle Entwicklung: eine separate Vektordatenbank, eine externe LLM-API sowie eine Abruf- und Schreibschicht, die aufgebaut und gewartet werden muss.
Aus Sicht der Souveränität ist dieses Modell standardmäßig unbedenklich. Die Plattform führt keine KI-Verarbeitung durch Dritte, keine externen Datenflüsse und kein vom Anbieter auferlegtes LLM ein. Was die Organisation mit KI macht, liegt ganz in ihrer eigenen Entscheidung und unterliegt ihrer eigenen Verantwortung.
Die praktische Einschränkung ist die Kehrseite dieser Medaille. Der Aufbau einer KI-Schicht in Produktionsqualität auf einer Plattform, die nicht dafür konzipiert wurde, ist ein umfangreiches Projekt – eines, das die meisten Organisationen auf unbestimmte Zeit aufschieben werden. Und „heute keine KI“ bedeutet ohne einen Plattformwechsel zunehmend „morgen kein Weg zur KI“. Mehrere leichtgewichtige Open-Source-Wikis – darunter bekannte Tools wie BookStack und DokuWiki – fallen in diese Kategorie.
Die Mehrheit der großen kommerziellen Wiki-Plattformen hat ein Modell eingeführt, bei dem KI integriert ist, die von einem oder mehreren vom Anbieter ausgewählten LLMs angetrieben und als Teil des Abonnements bereitgestellt wird. Der Kunde erhält die KI-Funktionen; der Anbieter kontrolliert den KI-Stack.
Die Funktionen in diesem Modell sind oft beeindruckend – Generierung direkt im Editor, semantische Suche, dialogbasierte Informationsgewinnung, autonome Agenten. Die Auswirkungen auf die Souveränität sind struktureller Natur. Bei den LLM-Anbietern handelt es sich in der Regel um große, in den USA ansässige KI-Unternehmen. Die Verarbeitung erfolgt auf einer Infrastruktur, die sich der Kontrolle des Kunden entzieht. Der Kunde kann weder ein anderes Modell einsetzen, noch die Verarbeitung in eine von ihm geprüfte Rechtsordnung verlagern, noch bestimmte Inhalte aus der KI-Pipeline heraushalten, ohne den Zugriff auf die Funktionen vollständig zu verlieren.
Ein weiteres Risiko dieses Modells besteht darin, dass der Anbieter die Nutzungsbedingungen für die KI einseitig ändern kann. Mehrere große Plattformen sind kürzlich dazu übergegangen, Kundeninhalte – in anonymisierter Form – zu nutzen, um ihre KI für alle Nutzer zu verbessern. Die Anonymisierung schützt den Inhalt strategischer Unterlagen, Compliance-Aufzeichnungen oder sensibler Geschäftsinhalte nicht davor, als Trainingssignal verwendet zu werden. Ein Opt-out ist in der Regel nur in den teuersten Tarifen verfügbar, und die Standardeinstellung ist ein Opt-in.
Im Mai 2026 kündigte ein großer Anbieter von Unternehmens-Wikis eine Änderung der Nutzungsbedingungen mit Wirkung zum August 2026 an: Metadaten der Kunden und In-App-Inhalte – darunter Inhalte von Wiki-Seiten, Projektbeschreibungen und Chat-Konversationen – werden zur Verbesserung der KI-Funktionen für alle Kunden auf der Plattform verwendet. Die Möglichkeit zum Opt-out ist auf die Enterprise-Stufe und bestimmte, für Compliance-Anforderungen qualifizierte Konten beschränkt. Kunden der Tarife „Free“ und „Standard“ haben keine Möglichkeit, die Bereitstellung von Metadaten abzulehnen.
Dies ist keine einzigartige oder isolierte Entwicklung. Sie spiegelt die wirtschaftliche Logik der vom Anbieter verwalteten KI wider: Der Anbieter trägt die Infrastrukturkosten für das LLM und deckt diese durch eine Kombination aus Preisgestaltung und Datennutzung wieder ein. Kunden, die keine „Enterprise“-Konditionen aushandeln können, akzeptieren Bedingungen, die sie möglicherweise nicht sorgfältig geprüft haben.
Zu den Plattformen dieser Kategorie gehören die führenden kommerziellen Wiki- und Wissensdatenbank-Produkte, darunter Confluence, Notion, Microsoft Loop und die meisten anderen SaaS-Wissensplattformen mit Hauptsitz in den USA. Die konkreten Bedingungen variieren; die strukturelle Ausgangslage – der Anbieter kontrolliert den KI-Stack, der Kunde kann diesen nicht ersetzen – ist jedoch in der gesamten Kategorie einheitlich.
Ein drittes Modell trennt die KI-Funktionen von der KI-Infrastruktur. Die Plattform stellt die Funktionen bereit – semantische Suche, Inhaltsgenerierung, dialogbasierte Informationsgewinnung –, verbindet diese jedoch mit dem LLM-Endpunkt, den das Unternehmen bereitstellt. Der Kunde wählt das Modell: einen kommerziellen Anbieter, den er geprüft und direkt unter Vertrag genommen hat, ein in seiner eigenen Infrastruktur bereitgestelltes Modell oder ein On-Premise-Modell ohne jegliche externe Anbindung.
Dieses Modell gibt dem Unternehmen eine sinnvolle Kontrolle über Fragen der Souveränität. Die Zuständigkeit für die KI-Verarbeitung wird durch das vom Unternehmen ausgewählte LLM bestimmt, nicht durch den Plattformanbieter. Das Training mit Kundendaten unterliegt der eigenen Vereinbarung des Unternehmens mit dem gewählten LLM-Anbieter, nicht den Standardbedingungen der Plattform. Sensible Bereiche der Wissensdatenbank können vollständig von der KI-Verarbeitung ausgeschlossen werden, indem sie einfach nicht mit dem LLM-Endpunkt verbunden werden.
Diese Architektur ist die natürliche Heimat für europäische souveräne Wiki-Plattformen – solche, die außerhalb der US-Gerichtsbarkeit aufgebaut und betrieben werden und bei denen Datenhoheit ein Gestaltungsprinzip und kein nachträgliches Compliance-Add-on ist. Mehrere Plattformen dieser Kategorie bauen aktiv BYOLLM-Fähigkeiten auf; der Reifegrad dieser Implementierungen variiert.
Phonemos implementiert das BYOLLM-Modell mit produktionsreifen Funktionen. Drei KI-Funktionen sind bereits live:
Phonemos wird in Bern, Schweiz, entwickelt und betrieben. An der Plattform oder ihrer Standardinfrastruktur sind keine US-Unternehmen beteiligt. Der CLOUD Act findet keine Anwendung. Kundeninhalte werden niemals dazu verwendet, die Phonemos-KI für andere Kunden zu trainieren oder zu verbessern. Die KI-Verarbeitung erfolgt innerhalb des von der Organisation ausgewählten LLM gemäß den Bedingungen, die diese Organisation mit ihrem gewählten Anbieter vereinbart hat.
Der Wiki-Markt deckt mittlerweile das gesamte Spektrum der KI-Governance ab: keine Funktionen, anbieterverwaltete KI mit festen Anbietern und US-amerikanischer Rechtshoheit sowie BYOLLM-Plattformen, die dem Unternehmen sinnvolle Kontrollmöglichkeiten bieten. Die Einordnung einer Plattform in dieses Spektrum wird zunehmend zu einem Beschaffungskriterium, das ebenso wichtig ist wie der Preis oder der Funktionsumfang.
Plattformen ohne eigene KI umgehen heute zwar die Frage der Souveränität – allerdings auf Kosten einer immer größer werdenden Funktionslücke und ohne klaren Weg, diese ohne erheblichen Entwicklungsaufwand oder einen Plattformwechsel zu schließen.
Anbietergeführte KI-Plattformen bieten leistungsfähige, produktionsreife Funktionen. Der Kompromiss ist struktureller Natur: Die Organisation akzeptiert die Wahl der LLM-Anbieter durch den Anbieter, dessen Rechtsordnung und zunehmend auch das Recht des Anbieters, Inhalte als Trainingsdaten zu verwenden. Für Organisationen mit strengen Anforderungen an die Daten-Governance sind dies keine Konfigurationsdetails – es handelt sich um Beschaffungsbeschränkungen.
BYOLLM-Plattformen lösen die Governance-Frage auf architektonischer Ebene. Unter den europäischen souveränen Wiki-Plattformen hat sich diese Architektur als der richtige Weg etabliert – die Frage bei jeder einzelnen Plattform ist, wie weit die Umsetzung bereits fortgeschritten ist. Für Organisationen, die derzeit eine Bewertung vornehmen, ist die Produktionsreife ebenso wichtig wie die architektonische Ausrichtung.
Der allgemeine Trend ist klar: KI wird zu einer zentralen Ebene der Funktionsweise von Wissensplattformen, und Anbieter beginnen, entsprechende Rechte an den Daten geltend zu machen, die über diese Plattformen fließen. Organisationen, die ihre Position zur KI-Governance noch nicht definiert haben – welche LLMs unter welchen Bedingungen und mit welchen Daten zugelassen sind –, werden mit diesen Fragen ihres Plattformanbieters konfrontiert werden, unabhängig davon, ob sie darauf vorbereitet sind oder nicht.