Stefan Haller
June 19, 2026
AI has arrived in the wiki market. Every major platform now offers some form of AI-assisted writing, semantic search, or conversational knowledge retrieval. For teams in unregulated environments, the choice is largely about features and price. For organisations operating in regulated industries, public administration, or anywhere with sensitive data, the choice has a more consequential dimension: who controls what the AI does with your knowledge, and under whose laws.
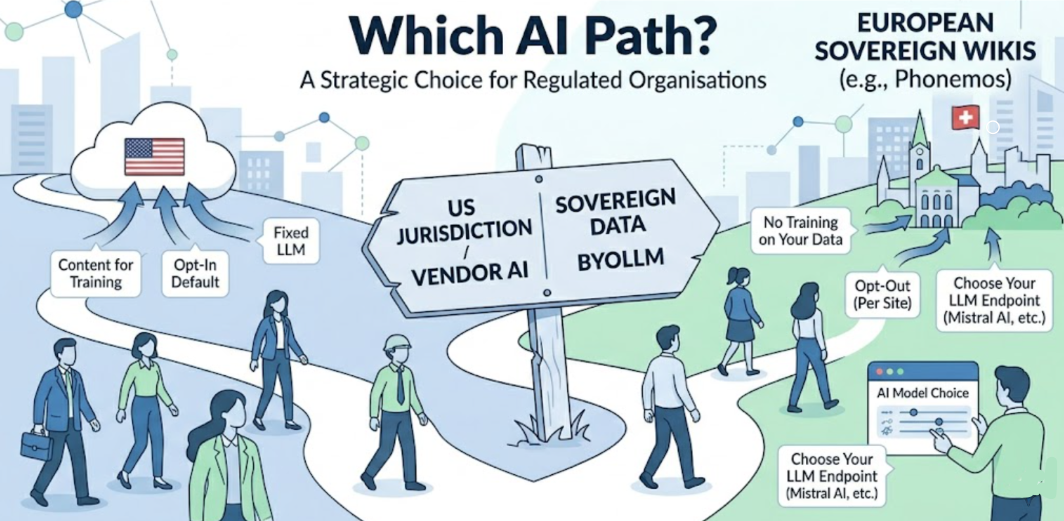
The wiki platforms available today do not all take the same approach to AI. Understanding the architectural models — and what each implies for data governance — is more useful than comparing feature lists, which change frequently. The architecture changes rarely.
When a wiki platform adds AI capabilities, several questions follow immediately:
The answers depend almost entirely on which of the three architectural models a platform has adopted.
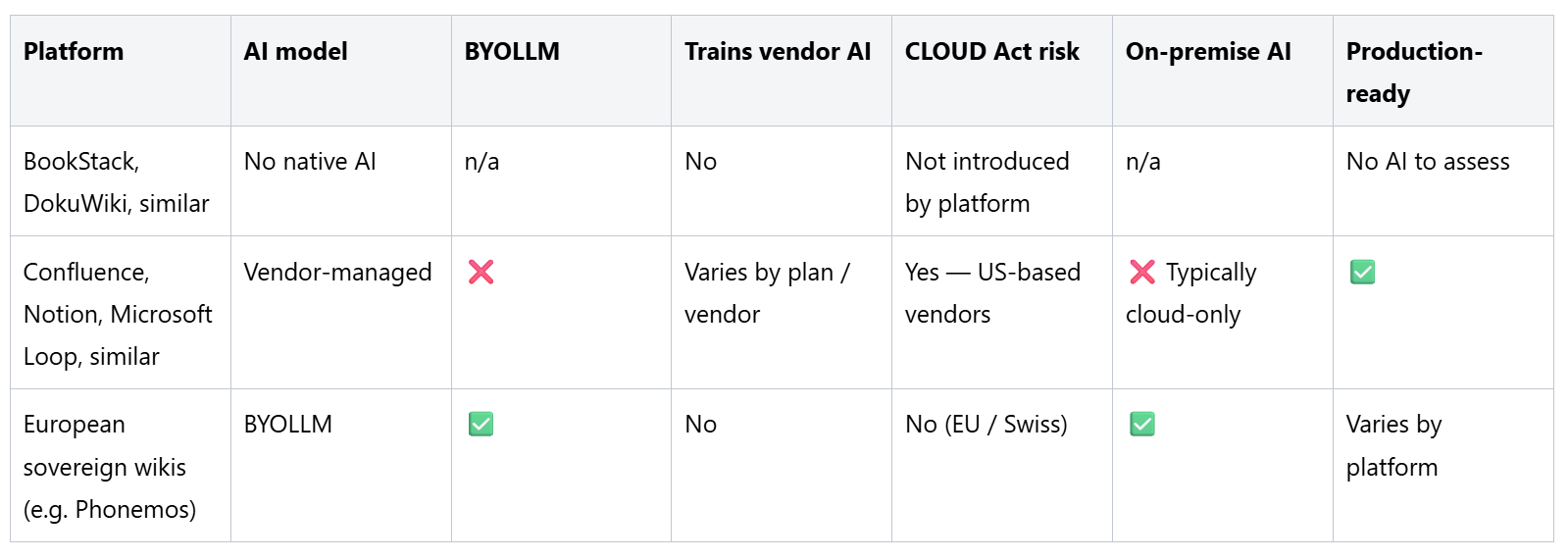
Some wiki platforms ship no AI capabilities at all. Search is keyword-based. There is no content generation, no semantic retrieval, no LLM integration of any kind. AI functionality, if needed, requires custom engineering: a separate vector database, an external LLM API, a retrieval and writing layer to build and maintain.
From a sovereignty perspective, this model is clean by default. The platform introduces no third-party AI processing, no external data flows, no vendor-imposed LLM. What the organisation does with AI is entirely its own choice and its own responsibility.
The practical limitation is the other side of that coin. Building a production-quality AI layer on top of a platform that was not designed for it is a significant project — one that most organisations will defer indefinitely. And “no AI today” increasingly means “no path to AI tomorrow” without a platform change. Several lightweight open-source wikis — including well-known tools like BookStack and DokuWiki — sit in this category.
The majority of major commercial wiki platforms have adopted a model where AI is built in, powered by one or more LLMs the vendor has selected, and delivered as part of the platform subscription. The customer gets the AI features; the vendor controls the AI stack.
The capabilities in this model are often impressive — in-editor generation, semantic search, conversational retrieval, autonomous agents. The sovereignty implications are structural. The LLM providers are typically major US-based AI companies. The processing happens on infrastructure outside the customer’s control. The customer cannot substitute a different model, route processing to a jurisdiction they have assessed, or keep specific content away from the AI pipeline without losing access to the features entirely.
A further risk in this model is the vendor’s ability to change the terms of AI use unilaterally. Several major platforms have recently moved to use customer content — in de-identified form — to improve their AI for all users. De-identification does not protect the substance of strategic documentation, compliance records, or sensitive business content from being used as training signal. Opt-out is typically available only on the most expensive tiers, and the default is opt-in.
In May 2026, one major enterprise wiki vendor announced a terms change effective August 2026: customer metadata and in-app content — including wiki page content, project descriptions, and chat conversations — will be used to improve AI features for all customers on the platform. Opt-out is restricted to the Enterprise tier and certain compliance-qualified accounts. Free and Standard plan customers have no opt-out for metadata contribution.
This is not a unique or isolated development. It reflects the economic logic of vendor-managed AI: the vendor bears the infrastructure cost of the LLM and recovers it through a combination of pricing and data. Customers who cannot negotiate Enterprise terms are accepting conditions they may not have reviewed carefully.
Platforms in this category include the leading commercial wiki and knowledge-base products, including Confluence, Notion, Microsoft Loop, and most other US-headquartered SaaS knowledge platforms. The specific terms vary; the structural position — vendor controls the AI stack, customer cannot substitute — is consistent across the category.
A third model separates the AI features from the AI infrastructure. The platform provides the capabilities — semantic search, content generation, conversational retrieval — but connects them to whichever LLM endpoint the organisation supplies. The customer chooses the model: a commercial provider they have assessed and contracted with directly, a model deployed in their own infrastructure, or an on-premise model with no external connectivity at all.
This model gives the organisation meaningful control over the sovereignty questions. The jurisdiction of AI processing is determined by the LLM the organisation selects, not by the platform vendor. Training on customer data is governed by the organisation’s own agreement with its chosen LLM provider, not by the platform’s standard terms. Sensitive areas of the knowledge base can be excluded from AI processing entirely by simply not connecting them to the LLM endpoint.
This architecture is the natural home for European sovereign wiki platforms — those built and operated outside US jurisdiction, with data sovereignty as a design principle rather than a compliance add-on. Several platforms in this category are actively building BYOLLM capabilities; the maturity of those implementations varies.
Phonemos implements the BYOLLM model with production-ready capabilities. Three AI features are live:
Phonemos is developed and operated in Bern, Switzerland. No US companies are involved in the platform or its default infrastructure. The CLOUD Act does not apply. Customer content is never used to train or improve Phonemos AI for other customers. AI processing happens within the LLM the organisation selects, under the terms that organisation has agreed with its chosen provider.
The wiki market now covers the full spectrum on AI governance: no capability, vendor-managed AI with fixed providers and US jurisdiction, and BYOLLM platforms that give the organisation meaningful control. Where a platform sits on that spectrum is increasingly a procurement criterion as significant as price or feature set.
Platforms with no native AI sidestep the sovereignty question today — but at the cost of an increasingly wide capability gap and no clear path to closing it without significant custom engineering or a platform change.
Vendor-managed AI platforms offer capable, production-ready features. The trade-off is structural: the organisation accepts the vendor’s choice of LLM providers, the vendor’s jurisdiction, and increasingly the vendor’s right to use content as training data. For organisations with strict data governance requirements, these are not configuration details — they are procurement constraints.
BYOLLM platforms resolve the governance question architecturally. Among European sovereign wiki platforms, this architecture is well established as the right direction — the question for any given platform is how far along the implementation is. For organisations evaluating now, production readiness matters as much as architectural intent.
The broader trend is clear: AI is becoming a core layer of how knowledge platforms work, and vendors are beginning to assert corresponding rights over the data that flows through it. Organisations that have not yet defined their AI governance position — which LLMs are approved, under what conditions, with what data — will face these questions from their platform vendor whether they are ready or not.