Stefan Haller
June 19, 2026
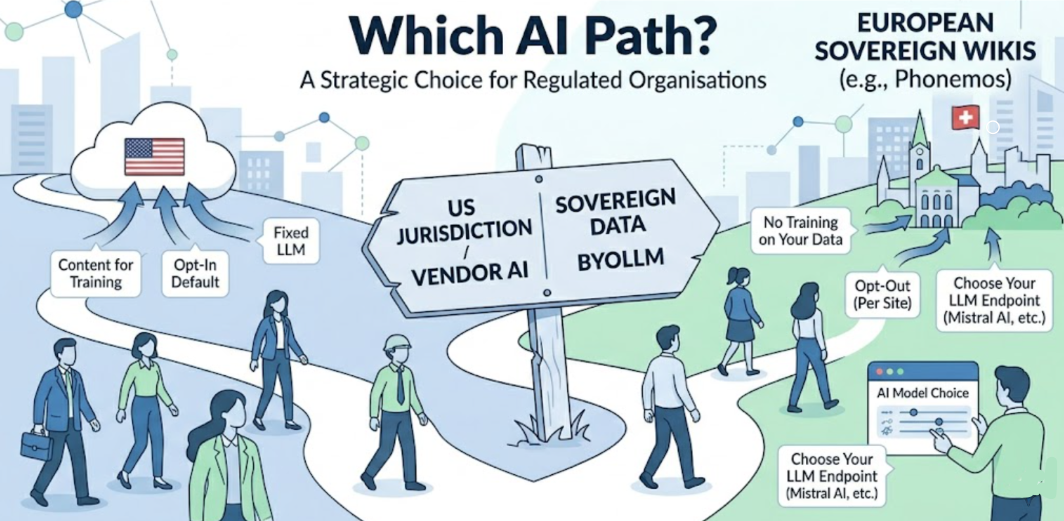
L’IA a fait son entrée sur le marché des wikis. Toutes les grandes plateformes proposent désormais, sous une forme ou une autre, des fonctionnalités d’aide à la rédaction assistée par l’IA, de recherche sémantique ou de recherche conversationnelle de connaissances. Pour les équipes évoluant dans des environnements non réglementés, le choix repose essentiellement sur les fonctionnalités et le prix. Pour les organisations opérant dans des secteurs réglementés, l’administration publique ou tout autre domaine traitant des données sensibles, ce choix revêt une dimension plus importante : qui contrôle ce que l’IA fait de vos connaissances, et en vertu de quelles lois.
Les plateformes wiki disponibles aujourd’hui n’adoptent pas toutes la même approche de l’IA. Comprendre les modèles architecturaux — et ce que chacun implique en matière de gouvernance des données — est plus utile que de comparer des listes de fonctionnalités, qui changent fréquemment. L’architecture, en revanche, change rarement.
Lorsqu’une plateforme wiki intègre des capacités d’IA, plusieurs questions se posent immédiatement :
Les réponses dépendent presque entièrement du modèle architectural (parmi les trois) adopté par la plateforme.
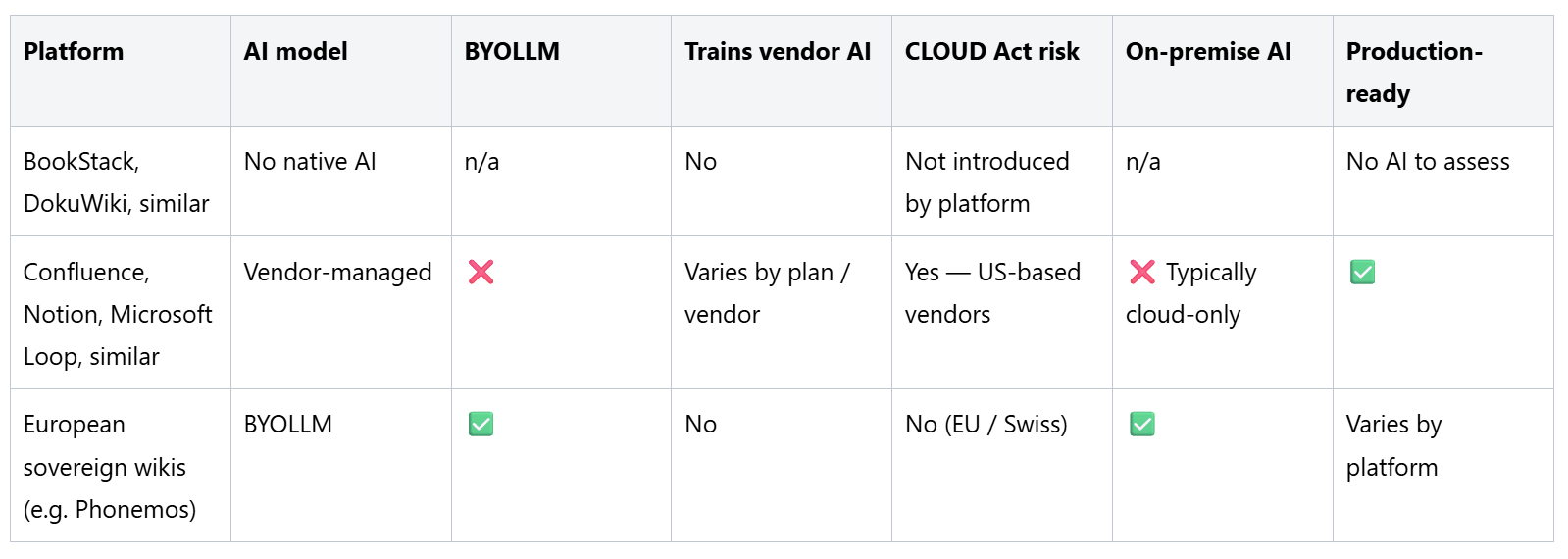
Certaines plateformes wiki ne proposent aucune fonctionnalité d’IA. La recherche s’effectue par mots-clés. Il n’y a ni génération de contenu, ni recherche sémantique, ni intégration de LLM d’aucune sorte. Si nécessaire, les fonctionnalités d’IA nécessitent un développement sur mesure : une base de données vectorielle distincte, une API LLM externe, ainsi qu’une couche de recherche et de rédaction à mettre en place et à maintenir.
Du point de vue de la souveraineté, ce modèle est par défaut irréprochable. La plateforme n’introduit aucun traitement d’IA tiers, aucun flux de données externe, aucun LLM imposé par un fournisseur. Ce que l’organisation fait avec l’IA relève entièrement de son propre choix et de sa propre responsabilité.
La limite pratique constitue le revers de la médaille. Construire une couche d’IA de qualité opérationnelle par-dessus une plateforme qui n’a pas été conçue à cet effet est un projet d’envergure — un projet que la plupart des organisations repousseront indéfiniment. Et « pas d’IA aujourd’hui » signifie de plus en plus « pas de voie vers l’IA demain » sans changement de plateforme. Plusieurs wikis open source légers — y compris des outils bien connus comme BookStack et DokuWiki — entrent dans cette catégorie.
La majorité des grandes plateformes wiki commerciales ont adopté un modèle dans lequel l’IA est intégrée, alimentée par un ou plusieurs modèles de langage (LLM) sélectionnés par le fournisseur, et fournie dans le cadre de l’abonnement à la plateforme. Le client bénéficie des fonctionnalités d’IA ; le fournisseur contrôle la pile d’IA.
Les capacités de ce modèle sont souvent impressionnantes : génération directement dans l’éditeur, recherche sémantique, recherche conversationnelle, agents autonomes. Les implications en matière de souveraineté sont structurelles. Les fournisseurs de LLM sont généralement de grandes entreprises d’IA basées aux États-Unis. Le traitement s’effectue sur une infrastructure échappant au contrôle du client. Ce dernier ne peut pas remplacer le modèle par un autre, acheminer le traitement vers une juridiction qu’il a évaluée, ni exclure certains contenus du pipeline d’IA sans perdre complètement l’accès aux fonctionnalités.
Un autre risque lié à ce modèle réside dans la capacité du fournisseur à modifier unilatéralement les conditions d’utilisation de l’IA. Plusieurs grandes plateformes ont récemment décidé d’utiliser le contenu de leurs clients — sous forme anonymisée — afin d’améliorer leur IA pour l’ensemble des utilisateurs. L’anonymisation n’empêche pas que le contenu de documents stratégiques, de dossiers de conformité ou d’informations commerciales sensibles soit utilisé comme données d’entraînement. La possibilité de se désinscrire n’est généralement disponible que sur les formules les plus onéreuses, et le paramètre par défaut est l’inscription automatique.
En mai 2026, un grand fournisseur de wikis d’entreprise a annoncé une modification de ses conditions d’utilisation prenant effet en août 2026 : les métadonnées des clients et le contenu de l’application — y compris le contenu des pages wiki, les descriptions de projets et les conversations par chat — seront utilisés pour améliorer les fonctionnalités d’IA pour tous les clients de la plateforme. La possibilité de se désinscrire est réservée au niveau « Enterprise » et à certains comptes répondant à des critères de conformité. Les clients des formules « Free » et « Standard » n’ont pas la possibilité de refuser la contribution de leurs métadonnées.
Il ne s’agit pas d’une évolution unique ou isolée. Elle reflète la logique économique de l’IA gérée par le fournisseur : ce dernier supporte le coût d’infrastructure du modèle de langage à grande échelle (LLM) et le récupère grâce à une combinaison de tarification et de données. Les clients qui ne peuvent pas négocier les conditions du forfait « Enterprise » acceptent des conditions qu’ils n’ont peut-être pas examinées attentivement.
Les plateformes de cette catégorie comprennent les principaux produits commerciaux de type wiki et de base de connaissances, notamment Confluence, Notion, Microsoft Loop et la plupart des autres plateformes de connaissances SaaS dont le siège social est situé aux États-Unis. Les conditions spécifiques varient ; la position structurelle — le fournisseur contrôle la pile d’IA, le client ne peut pas la remplacer — est cohérente dans toute la catégorie.
Un troisième modèle sépare les fonctionnalités d’IA de l’infrastructure d’IA. La plateforme fournit les capacités — recherche sémantique, génération de contenu, recherche conversationnelle — mais les connecte à n’importe quel point de terminaison LLM fourni par l’organisation. Le client choisit le modèle : un fournisseur commercial qu’il a évalué et avec lequel il a conclu un contrat directement, un modèle déployé dans sa propre infrastructure, ou un modèle sur site sans aucune connectivité externe.
Ce modèle confère à l’organisation un contrôle significatif sur les questions de souveraineté. La juridiction applicable au traitement par IA est déterminée par le LLM choisi par l’organisation, et non par le fournisseur de la plateforme. L’entraînement sur les données du client est régi par le contrat que l’organisation a conclu avec le fournisseur de LLM de son choix, et non par les conditions générales de la plateforme. Les domaines sensibles de la base de connaissances peuvent être totalement exclus du traitement par IA en évitant simplement de les connecter au point de terminaison du LLM.
Cette architecture est le cadre naturel des plateformes wiki souveraines européennes — celles qui sont construites et exploitées en dehors de la juridiction américaine, et pour lesquelles la souveraineté des données est un principe de conception plutôt qu’un simple ajout de conformité. Plusieurs plateformes de cette catégorie développent activement des capacités BYOLLM ; le degré de maturité de ces implémentations varie.
Phonemos met en œuvre le modèle BYOLLM avec des fonctionnalités prêtes pour la production. Trois fonctionnalités d’IA sont opérationnelles :
Phonemos est développé et exploité à Berne, en Suisse. Aucune entreprise américaine n’est impliquée dans la plateforme ni dans son infrastructure par défaut. Le CLOUD Act ne s’applique pas. Le contenu des clients n’est jamais utilisé pour entraîner ou améliorer l’IA de Phonemos au profit d’autres clients. Le traitement par IA s’effectue au sein du LLM choisi par l’organisation, selon les conditions que celle-ci a convenues avec le fournisseur de son choix.
Le marché des wikis couvre désormais tout le spectre de la gouvernance de l’IA : absence de capacité, IA gérée par le fournisseur avec des prestataires fixes et relevant de la juridiction américaine, et plateformes BYOLLM qui offrent à l’organisation un contrôle significatif. La position d’une plateforme sur ce spectre devient de plus en plus un critère d’achat aussi important que le prix ou l’ensemble des fonctionnalités.
Les plateformes sans IA native contournent aujourd’hui la question de la souveraineté — mais au prix d’un déficit de capacités de plus en plus important et de l’absence de voie claire pour y remédier sans recourir à une ingénierie sur mesure importante ou à un changement de plateforme.
Les plateformes d’IA gérées par le fournisseur offrent des fonctionnalités performantes et prêtes à l’emploi. Le compromis est d’ordre structurel : l’organisation accepte le choix du fournisseur en matière de fournisseurs de LLM, la juridiction du fournisseur et, de plus en plus, le droit de ce dernier à utiliser le contenu comme données d’entraînement. Pour les organisations soumises à des exigences strictes en matière de gouvernance des données, il ne s’agit pas de détails de configuration, mais bien de contraintes d’achat.
Les plateformes BYOLLM résolvent la question de la gouvernance au niveau architectural. Parmi les plateformes wiki souveraines européennes, cette architecture s’impose clairement comme la bonne voie à suivre — la question pour une plateforme donnée est de savoir où en est sa mise en œuvre. Pour les organisations qui évaluent actuellement ces solutions, la maturité opérationnelle importe autant que l’intention architecturale.
La tendance générale est claire : l’IA devient un élément central du fonctionnement des plateformes de connaissances, et les fournisseurs commencent à revendiquer des droits correspondants sur les données qui y transitent. Les organisations qui n’ont pas encore défini leur position en matière de gouvernance de l’IA — quels modèles de langage à grand échelle (LLM) sont approuvés, dans quelles conditions et avec quelles données — seront confrontées à ces questions de la part de leur fournisseur de plateforme, qu’elles y soient prêtes ou non.